Regression With Scikit Learn (Part 3)
Published: Aug 18, 2021
Last updated: Aug 18, 2021
This is Day 31 of the #100DaysOfPython challenge.
This post will use the scikit-learn library to demonstrate how we can use k-fold cross validation.
We will be working from the code written in part two.
Source code can be found on my GitHub repo okeeffed/regression-with-scikit-learn-part-three.
Prerequisites
- Familiarity Conda package, dependency and virtual environment manager. A handy additional reference for Conda is the blog post "The Definitive Guide to Conda Environments" on "Towards Data Science".
- Familiarity with JupyterLab. See here for my post on JupyterLab.
- These projects will also run Python notebooks on VSCode with the Jupyter Notebooks extension. If you do not use VSCode, it is expected that you know how to run notebooks (or alter the method for what works best for you).
Getting started
Let's first clone the code from part two into the regression-with-scikit-learn-part-three directory.
# Make the `regression-with-scikit-learn-part-three` directory $ git clone https://github.com/okeeffed/regression-with-scikit-learn-part-two.git regression-with-scikit-learn-part-three $ cd regression-with-scikit-learn-part-three
We can now begin adding code to our notebook at docs/linear_regression.ipynb.
Cross-validation
At this stage, the docs/linear_regression.ipynb notebook currently has cells up to the point where we have created a train/test split regressor and scored all of our test data.
At the moment, we have only done one train/test split. What are the potential issues with this?
If we calculate R^2 on the test set, the value is dependent on how we split up data. The test set may have peculiarities that may make is hard to generalize.
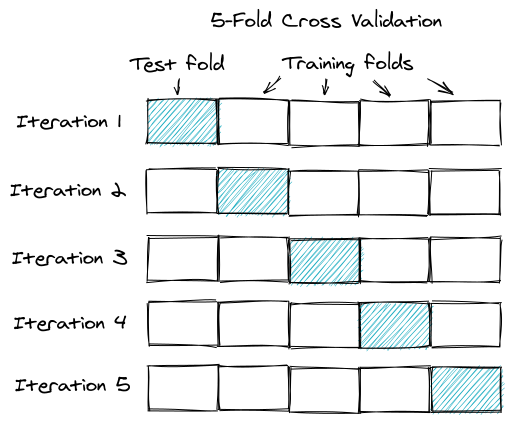
The technique we use to work around this is called k-fold cross-validation. In our case specific, we will use k=5 where k is the number of splits we do. In this particular case, using k=5 with five splits is known as 5-fold cross-validation.
It works by splitting the data into k equal parts (5 in this case), and then using the first part as the test set and the last k-1 parts as the training sets (also referred to as folds).
For split one, we will hold out the first fold as a test set, and fit our model on the remaining four folds, predict on the test set and compute the metric of interest.
For split two, we hold out on the second fold as the test set and fit our model on the remaining 4 folds, predict on the test set and compute the metric of interest.
This repeated until we end up with five values of R^2. From here, we could calculate mean, median as well as 95% confidence intervals.

5-Fold Cross Validation diagram
The trade-off with k-folds is that the large the value of k, the more computationally expensive it will be.
This method will prevent us from becoming dependent on the particular train/test split we use.
Applying cross-validation
In our file docs/regression-with-scikit-learn-part-three, we can add the following to a new cell.
from sklearn.model_selection import cross_val_score from sklearn.linear_model import LinearRegression import numpy as np reg = LinearRegression() # cv defines the number of folds # the score reported is R^2 cv_results = cross_val_score(reg, X, y, cv=5) print(cv_results) # [ 0.63919994 0.71386698 0.58702344 0.07923081 -0.25294154] np.mean(cv_results) # 0.3532759243958772
The above will calculate the R^2 value (the default) for each of the five folds and we can use numpy to compute the mean.
In our case, the R^2 values calculated for the 5 folds are [ 0.63919994 0.71386698 0.58702344 0.07923081 -0.25294154] with a mean value of 0.3532759243958772.
Summary
Today's post demonstrated how to perform a k-folds cross validation with linear regression (in particular the 5-folds cross validation on our set).
In the final post on linear regression tomorrow, we will explore how to use regression with regularization.
Resources and further reading
Photo credit: anniespratt


Dennis O'Keeffe
Melbourne, Australia
1,200+ PEOPLE ALREADY JOINED ❤️️
Get fresh posts + news direct to your inbox.
No spam. We only send you relevant content.
Regression With Scikit Learn (Part 3)
Introduction
